桔妹导读:滴滴ElasticSearch平台承接了公司内部所有使用ElasticSearch的业务,包括核心搜索、RDS从库、日志检索、安全数据分析、指标数据分析等等。平台规模达到了3000+节点,5PB 的数据存储,超过万亿条数据。平台写入的峰值写入TPS达到了2000w/s,每天近 10 亿次检索查询。为了承接这么大的体量和丰富的使用场景,滴滴ElasticSearch需要 w397090770 4年前 (2020-08-19) 1452℃ 0评论8喜欢
Spark 1.1.1于美国时间的2014年11月26日正式发布。基于branch-1.1分支,主要修复了一些bug。推荐所有的1.1.0用户更新到这个稳定版本。本次更新共有55位开发者参与。 spark.shuffle.manager仍然使用Hash作为默认值,说明了SORT的Shuffle还不怎么成熟。等待1.2版本吧。Fixes Spark 1.1.1修复了几个组件的bug。在下面将会列出一些代表性的b w397090770 10年前 (2014-11-28) 3339℃ 0评论5喜欢
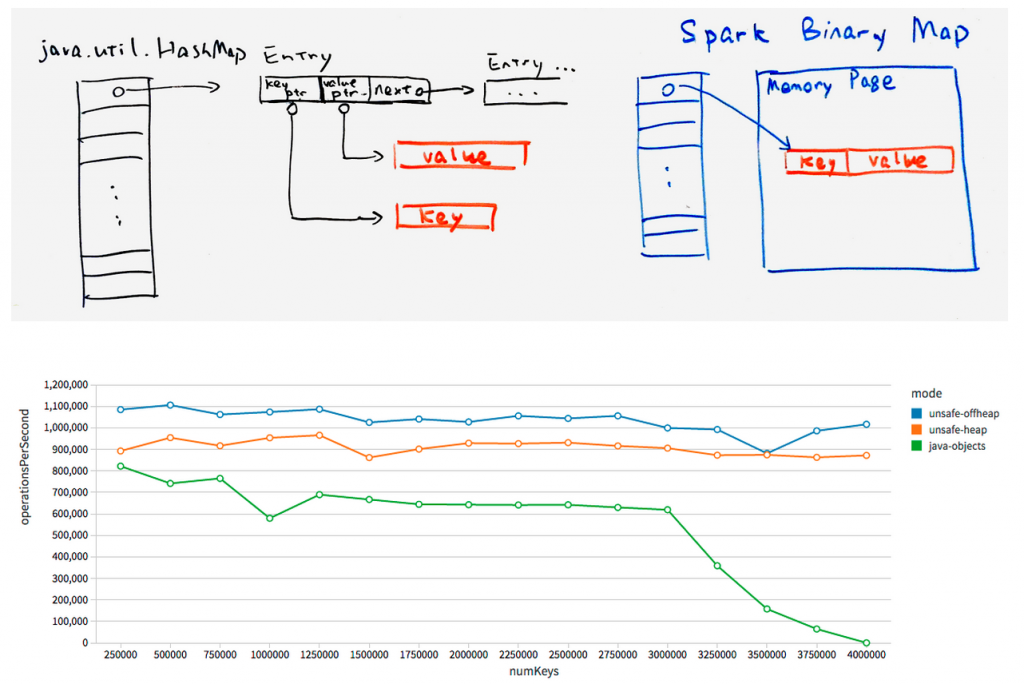
在之前的博文中,我们回顾和总结了2014年Spark在性能提升上所做的努力。本篇博文中,我们将为你介绍性能提升的下一阶段——Tungsten。在2014年,我们目睹了Spark缔造大规模排序的新世界纪录,同时也看到了Spark整个引擎的大幅度提升——从Python到SQL再到机器学习。 Tungsten项目将是Spark自诞生以来内核级别的最大改动,以 w397090770 10年前 (2015-05-04) 4880℃ 1评论4喜欢
本文讲解的Hive和HBase整合意思是使用Hive读取Hbase中的数据。我们可以使用HQL语句在HBase表上进行查询、插入操作;甚至是进行Join和Union等复杂查询。此功能是从Hive 0.6.0开始引入的,详情可以参见HIVE-705。Hive与HBase整合的实现是利用两者本身对外的API接口互相进行通信,相互通信主要是依靠hive-hbase-handler-1.2.0.jar工具里面的类实现 w397090770 8年前 (2016-07-31) 17459℃ 0评论42喜欢
上海Spark Meetup第六次聚会将于2015年08月08日下午1:30 PM to 5:00 PM在上海市杨浦云计算创新基地发展有限公司举办,详细地址上海市杨浦区伟德路6号云海大厦13楼。本次聚会由Intel举办。大会主题主讲题目:Tachyon: 内存为中心可容错的分布式存储系统 摘要:在越来越多的大数据应用场景诸如机器学习,数据分析等, 内存成 w397090770 9年前 (2015-08-28) 4462℃ 0评论1喜欢
《Spark Streaming作业提交源码分析接收数据篇》、《Spark Streaming作业提交源码分析数据处理篇》 最近一段时间在使用Spark Streaming,里面遇到很多问题,只知道参照官方文档写,不理解其中的原理,于是抽了一点时间研究了一下Spark Streaming作业提交的全过程,包括从外部数据源接收数据,分块,拆分Job,提交作业全过程。 w397090770 10年前 (2015-04-28) 9201℃ 2评论9喜欢
《Spark RDD缓存代码分析》 《Spark Task序列化代码分析》 《Spark分区器HashPartitioner和RangePartitioner代码详解》 《Spark Checkpoint读操作代码分析》 《Spark Checkpoint写操作代码分析》 上次我对Spark RDD缓存的相关代码《Spark RDD缓存代码分析》进行了简要的介绍,本文将对Spark RDD的checkpint相关的代码进行相关的 w397090770 9年前 (2015-11-25) 8918℃ 5评论14喜欢
写在前面的话,学Hive这么久了,发现目前国内还没有一本完整的介绍Hive的书籍,而且互联网上面的资料很乱,于是我决定写一些关于《Hive的那些事》序列文章,分享给大家。我会在接下来的时间整理有关Hive的资料,如果对Hive的东西感兴趣,请关注本博客。https://www.iteblog.com/archives/tag/hive-technology/ Hive最初是应Facebook每天 w397090770 11年前 (2013-12-18) 16853℃ 2评论31喜欢
由 Ahana 工程师 Vivek Bharathan、David E. Simmen 以及 George Wang 编写的《Learning and Operating Presto》图书计划在2021年11月发布,不过预览版已经可以下载了。如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop图书描述Presto 社区自2012年诞生于 Facebook 后迅速发展起来。但是,即使对最有经验的工程师来说 w397090770 4年前 (2021-01-21) 518℃ 0评论2喜欢
Apache Spark是目前非常强大的分布式计算框架。其简单易懂的计算框架使得我们很容易理解。虽然Spark是在操作大数据集上很有优势,但是它仍然需要将数据持久化存储,HDFS是最通用的选择,和Spark结合使用,因为它基于磁盘的特点,导致在实时应用程序中会影响性能(比如在Spark Streaming计算中)。而且Spark内置就不支持事务提交( w397090770 10年前 (2015-04-22) 10205℃ 0评论8喜欢
下面的大数据学习电子书我会陆续上传,敬请关注。一、Hadoop1、Hadoop Application Architectures2、Hadoop: The Definitive Guide, 4th Edition3、Hadoop Security Protecting Your Big Data Platform4、Field Guide to Hadoop An Introduction to Hadoop, Its Ecosystem, and Aligned Technologies5、Hadoop Operations A Guide for Developers and Administrators6、Hadoop Backup and Recovery Solutions w397090770 9年前 (2015-08-11) 20468℃ 2评论56喜欢
今年是我创建这个微信公众号的第五年,五年来,收获了6.8万粉丝。这个数字,在自媒体圈子,属于十八线小规模的那种,但是在纯技术圈,还是不错的成绩,我很欣慰。我花在这个号上面的时间挺多的。我平时下班比较晚,一般下班到家了,老婆带着孩子已经安睡了,我便轻手轻脚的拿出电脑,带上耳机,开始我一天的知识盘 w397090770 5年前 (2019-08-13) 5650℃ 2评论33喜欢
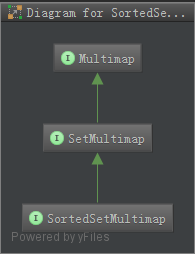
[caption id="attachment_756" align="aligncenter" width="195"] Gauva学习之SortedSetMultimap[/caption] SortedSetMultimap是一个接口,它的继承关系如上所示。继承了SortedSetMultimap接口的类中key所对应的value是有序的。因为SortedSetMultimap的子类中key所对应的value是有序的,所以SortedSetMultimap重写了SetMultimap中的以下四个方法:[code lang="JAVA"]@OverrideSortedSet< w397090770 11年前 (2013-09-27) 4144℃ 0评论3喜欢
这是一份迟来的年终报告,本来昨天就要发出来的,实在是没忙开,今天我就把它当作新年礼物送给各位看官,以下文章都是我结合日常工作、学习,每当“夜深人静"的时候写出来的一些小总结,希望能给大家一些技术上的帮助。关注我的朋友都知道,我在今年八月份发了一篇文章,里面整理了我五年来写在这个公众号上面的原 w397090770 5年前 (2020-01-04) 1386℃ 0评论1喜欢
来自于requests的灵感,因为它很简单;并且由lxml驱动,因为它速度很快。 Newspaper是一个惊人的新闻、全文以及文章元数据抽取开源的Python类库,这个类库支持10多种语言,所有的东西都是用unicode编码的。我们可以使用下面命令查看:[code lang="python"]/** * User: 过往记忆 * Date: 2015-05-20 * Time: 下午23:14 * bolg: * 本文地 w397090770 10年前 (2015-05-20) 2775℃ 0评论0喜欢
Spark Data Source API是从Spark 1.2开始提供的,它提供了可插拔的机制来和各种结构化数据进行整合。Spark用户可以从多种数据源读取数据,比如Hive table、JSON文件、Parquet文件等等。我们也可以到http://spark-packages.org/(这个网站貌似现在不可以访问了)网站查看Spark支持的第三方数据源工具包。本文将介绍新的Spark数据源包,通过它我们 w397090770 9年前 (2015-10-21) 3896℃ 0评论4喜欢
Storm和Spark Streaming两个都是分布式流处理的开源框架。但是这两者之间的区别还是很大的,正如你将要在下文看到的。处理模型以及延迟 虽然两框架都提供了可扩展性(scalability)和可容错性(fault tolerance),但是它们的处理模型从根本上说是不一样的。Storm可以实现亚秒级时延的处理,而每次只处理一条event,而Spark Streaming w397090770 10年前 (2015-03-12) 16674℃ 1评论6喜欢
活动内容2015年下半年华东地区scala爱好者聚会,这次活动有杭州九言科技(代表作是In App)提供场地。本次活动内容不局限scala也包含一些创业公司的技术架构地点:杭州西湖区万塘路8号黄龙时代广场A座1802时间:2015年12月26日 13:00 ~ 2015年12月26日 17:30限制: 限额35人费用:免费活动安排1) 《scala和storm下的流式计算 w397090770 9年前 (2015-12-16) 2408℃ 0评论6喜欢
本文根据2016年4月北京Apache Kylin Meetup上的分享讲稿整理,略有删节。美团各业务线存在大量的OLAP分析场景,需要基于Hadoop数十亿级别的数据进行分析,直接响应分析师和城市BD等数千人的交互式访问请求,对OLAP服务的扩展性、稳定性、数据精确性和性能均有很高要求。本文主要介绍美团的具体OLAP需求,如何将Kylin应用到实际场景 w397090770 8年前 (2016-07-17) 9694℃ 0评论9喜欢
《Spark Streaming和Kafka整合开发指南(一)》 《Spark Streaming和Kafka整合开发指南(二)》 在本博客的《Spark Streaming和Kafka整合开发指南(一)》文章中介绍了如何使用基于Receiver的方法使用Spark Streaming从Kafka中接收数据。本文将介绍如何使用Spark 1.3.0引入的Direct API从Kafka中读数据。 和基于Receiver接收数据不一样,这种方式 w397090770 10年前 (2015-04-21) 28423℃ 1评论26喜欢
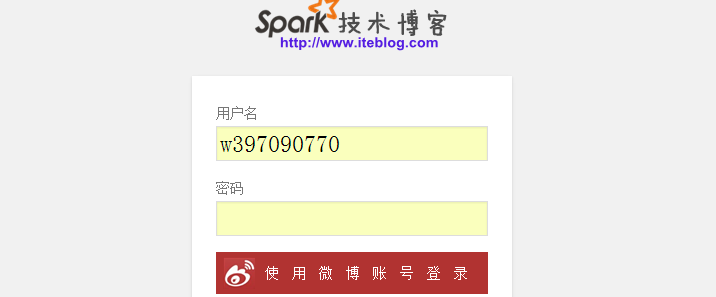
经过一晚上的奋战终于通过调用新浪登录的登录API替代Wordpress内置的登录注册模块。只要你有新浪微博帐号即可绑定到本博客。添加微博登录功能主要解决两个问题:(1)、方便用户登录/注册;(2)、防止机器人注册本网站。以下是登录页面图: 点击上面使用微博帐号登录即可调用微博登录。如果你是第一次登录,需 w397090770 10年前 (2015-04-04) 4991℃ 0评论3喜欢
本书于2015年03月出版,全书共19页,这里是完整版。 w397090770 9年前 (2015-08-21) 1859℃ 0评论3喜欢
我们已经在 这篇文章详细介绍了 Apache Spark Delta Lake 的事务日志是什么、主要用途以及如何工作的。那篇文章已经可以很好地给大家介绍 Delta Lake 的内部工作原理,原子性保证,本文为了学习的目的,带领大家从源码级别来看看 Delta Lake 事务日志的实现。在看本文时,强烈建议先看一下《深入理解 Apache Spark Delta Lake 的事务日志》文 w397090770 5年前 (2019-09-02) 1752℃ 0评论4喜欢
Spark Summit East 2016:视频,PPT Spark Summit East 2016会议于2016年2月16日至2月18日在美国纽约进行。总体来说,Spark Summit一年比一年火,单看纽约的峰会中,规模已从900人增加到500个公司的1300人,更吸引到更多大型公司的分享,包括Bloomberg、Capital One、Novartis、Comcast等公司。而在这次会议上,Databricks还发布了两款产品——Commu w397090770 9年前 (2016-02-27) 6180℃ 0评论9喜欢
本书于2017-07由Packt Publishing出版,作者Giuseppe Bonaccorso,全书580页。关注大数据猿(bigdata_ai)公众号及时获取最新大数据相关电子书、资讯等通过本书你将学到以下知识Acquaint yourself with important elements of Machine LearningUnderstand the feature selection and feature engineering processAssess performance and error trade-offs for Linear RegressionBuild a data model zz~~ 7年前 (2017-08-27) 4640℃ 0评论14喜欢
Starburst provides connectors to the most popular data sources included in many of these connectors are a number of exclusive enhancements. Many of Starburst’s connectors when compared with open source Trino have enhanced extensions such as parallelism, pushdown and table statistics, that drastically improve the overall performance. Parallelism distributes query processing across workers, and uses many connections to the data source a w397090770 3年前 (2022-04-15) 625℃ 0评论0喜欢
我们使用数据库可以快速访问业务数据,但是随着时间的推移,数据库会不断增长,提取信息所需的时间也会更长,数据操作成为瓶颈。这时候我们就需要对数据进行分区(partition)了。分区是将数据库或其组成元素划分为不同的独立部分。数据库分区通常是出于可管理性、性能或可用性或负载平衡的原因而进行的。在分布式数据 w397090770 5年前 (2020-05-14) 1081℃ 0评论2喜欢
《Spark Streaming和Kafka整合开发指南(一)》 《Spark Streaming和Kafka整合开发指南(二)》 Apache Kafka是一个分布式的消息发布-订阅系统。可以说,任何实时大数据处理工具缺少与Kafka整合都是不完整的。本文将介绍如何使用Spark Streaming从Kafka中接收数据,这里将会介绍两种方法:(1)、使用Receivers和Kafka高层次的API;(2) w397090770 10年前 (2015-04-19) 33709℃ 0评论33喜欢
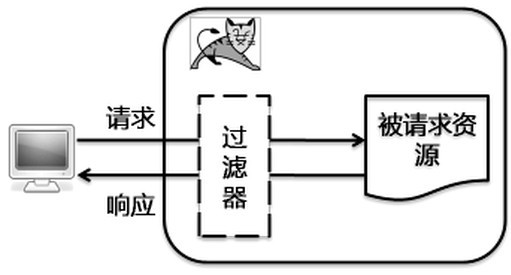
一、过滤器 从过滤器这个名字上可以得知就是在源数据和目标数据之间起到过滤作用的中间组件。例如家里用的纯净水过滤器,将自来水过滤为纯净水。过滤器是在Servlet2.3规范中引入的新功能,并在Servlet2.4规范中得到增强。它是在服务端运行的Web组件程序,可以截取客户端给服务器发的请求,也可以截取服务器给客户端的响应。 w397090770 11年前 (2013-08-01) 3694℃ 0评论5喜欢
什么是MathJax MathJax是一个显示网络上数学公式的开源JavaScript引擎库,它可以在所有浏览器上面工作,其中就支持LaTeX,MathML和AsciiMath 符号,里面的数字会被MathJax使用JavaScript引擎解析成HTML,SVG或者是MathML 方程式,然后在现代的浏览器里面显示。 它的设计目标是利用最新的web技术,构建一个支持math的web平台。支持主要的浏览 w397090770 10年前 (2015-04-15) 34825℃ 3评论42喜欢






![Hadoop等大数据学习相关电子书[共85本]](https://www.iteblog.com/wp-content/themes/yusi2.0/img/pic/8.jpg)






![[电子书]Machine Learning Algorithms PDF下载](https://www.iteblog.com/pic/books/Machine_Learning_Algorithms_iteblog.png)